Existing Feature Selection Algorithms

We Present Scaden A Deep Neural Network For Cell Deconvolution That Uses Gene Expression Information To Infer The In 2020 Rna Sequencing Deep Learning Gene Expression

4 Steps To Get Started In Machine Learning The Top Down Strategy For Beginners To Sta Machine Learning Deep Learning Data Science Learning Ai Machine Learning

Using Genetic Algorithm For Optimizing Recurrent Neural Network Genetic Algorithm Algorithm Optimization

Figure In 2020 Database System Database Management System Database Management

Pin On Ai Applications

On Many Eyes You Can 1 View And Discuss Visualizations 2 View And Discuss Data Sets 3 Create Vis Data Visualization Teaching Geography Technology Tools
This paper introduces concepts and algorithms of feature selection surveys existing feature selection algorithms for classification and clustering groups and compares different algorithms with a categorizing framework based on search strategies evaluation criteria and data mining tasks reveals unattempted combinations and provides guidelines in selecting feature selection.
Existing feature selection algorithms. Having too much data that is of little value or having too little data that is of. Weighted words are better comparison parameters than ordinary text because the weighted words tell more about the content of. This is where feature selection comes in.
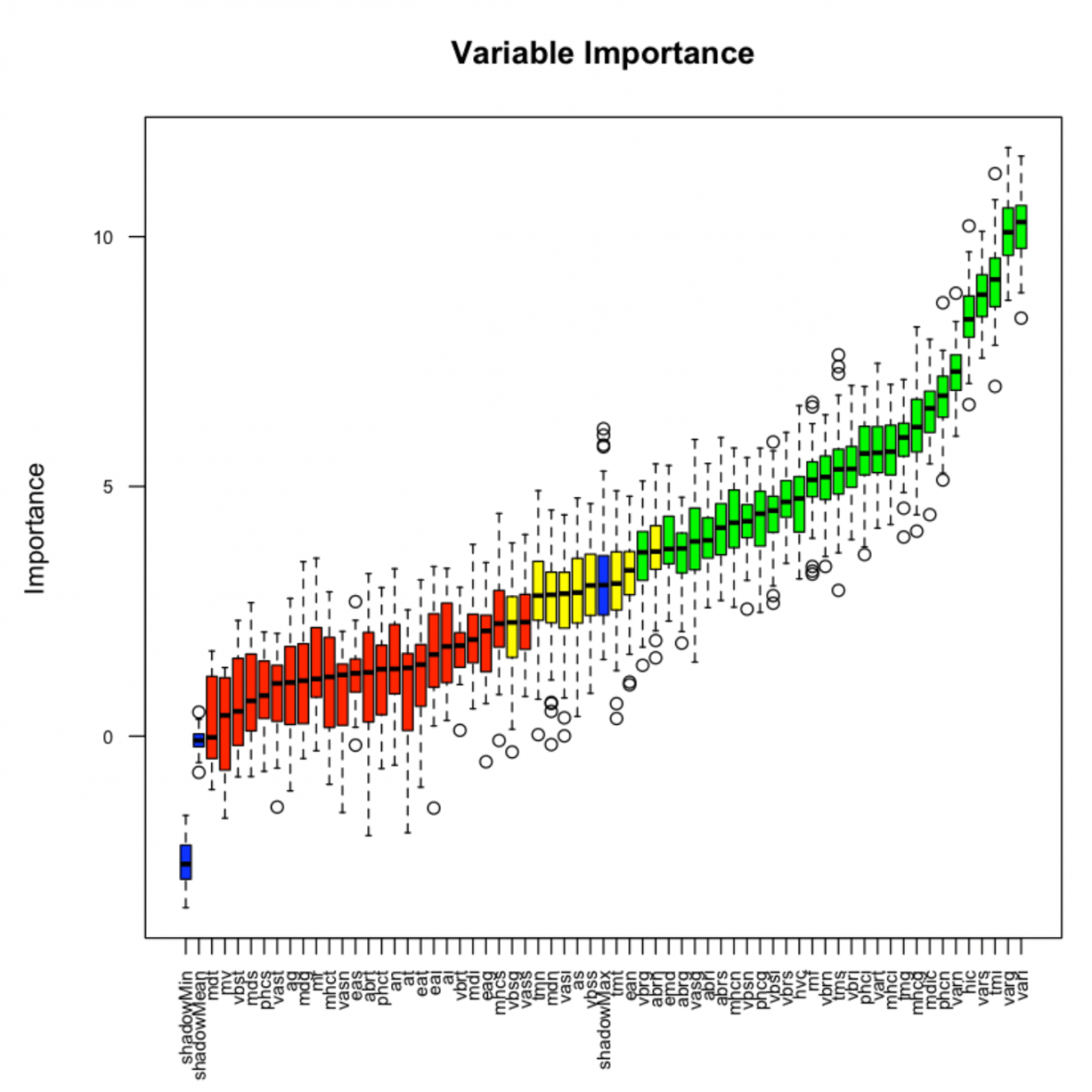
The analyst might perform feature engineering to add features and remove or modify existing data while the machine learning algorithm typically scores columns and validates their usefulness in the model. The comparison in figure 3 and figure 4 shows that our algorithm has better stats because the existing algorithm without the proposed feature selection algorithm uses the full documents which often leads to high noise. Tackling the feature selection problem of type 2 studied for many years by the statistical 18 as well as the machine learning 38 communities.
Research developed within the machine learning area is usually focused on the proposal of new algorithms theoretical learning results of existing al. As said before embedded methods use algorithms that have built in feature selection methods. We calculate feature importance using node impurities in each decision tree.
As mrmr approximates the combinatorial estimation problem with a series of much smaller problems each. By limiting the number of features we use rather than just feeding the model the unmodified data we can often speed up training and improve accuracy or both. In random forest the final feature importance is the average of all decision tree feature importance.
We can also use randomforest to select features based on feature importance.

Linear Attention Recurrent Neural Network Linear Attention Networking

Newgen Provider Contract Manager In 2020 Reviews Features Pricing Comparison Pat Research B2b Reviews Buying Guides Best Practices Business Intelligence Contract Management Decision Making
Feature Selection Ten Effective Techniques With Examples Ml

Essentials Of Machine Learning Algorithms With Python And R Codes With Images Machine Learning Basics Machine Learning Supervised Learning

What Is Data Science Data Science Data Scientist Data Science Learning

Evaluation Of Feature Selection Methods For Text Classification With Small Datasets Using Multiple Criteria Decision Making Methods Sciencedirect

Dr James Mccaffrey Of Microsoft Research Uses A Full Code Sample And Screenshots To Show How To Programma In 2020 Security Solutions Security Tools Excel Spreadsheets

Instrument Identification Tags Instruments Tags Lettering
Https Encrypted Tbn0 Gstatic Com Images Q Tbn And9gcr3az0 Obpwyui Wzpoxwf4q6m60bm4zkpkzw Usqp Cau

Algorithm Seminar Topics For Cse In 2020 Seminar Computer Science Engineering Topics

Poster Download Microsoft Business Intelligence At A Glance Business Intelligence Data Science Learning Data Science

Wps Wpa Tester Premium Screendshot 2 Wpa Wps Best Wifi

Abap On Sap Hana Part Iii Debugging In Adt Sapspot Sap Hana Adt
